Media Summary: This is a video recording of the following Okay hi everyone good morning it is 9 A.M here in Vancouver thank you so much for joining us in our tutorial This work aims on challenging the common design philosophy of the Vision Transformer (
All Things Vits Cvpr 2023 - Detailed Analysis & Overview
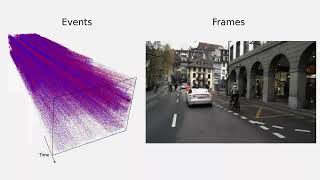
This is a video recording of the following Okay hi everyone good morning it is 9 A.M here in Vancouver thank you so much for joining us in our tutorial This work aims on challenging the common design philosophy of the Vision Transformer ( OmniObject3D: Large-Vocabulary 3D Object Dataset for Realistic Perception, Reconstruction and Generation project page: ... We present Recurrent Vision Transformers (RVTs), a novel backbone for object detection with event cameras. Event cameras ... Meta-Explore: Exploratory Hierarchical Vision-and-Language Navigation Using Scene Object Spectrum Grounding (
IEEE/CVF Conference on Computer Vision and Pattern Recognition





![[CVPR 2023] CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not](https://i.ytimg.com/vi/ImcQFsS1SfE/mqdefault.jpg)

![[CVPR 2023 Award Candidate] An Introduction to the OmniObject3D Dataset](https://i.ytimg.com/vi/UIGI5OjSZqc/mqdefault.jpg)
![[CVPR 2023] Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers](https://i.ytimg.com/vi/u2gb8Q20B2k/mqdefault.jpg)
![[CVPR2023 Tutorial Talk] Large Multimodal Models: Towards Building and Surpassing Multimodal GPT-4](https://i.ytimg.com/vi/mkI7EPD1vp8/mqdefault.jpg)
![[CVPR 2023] Meta-Explore: Exploratory Hierarchical Vision-and-Language Navigation Using Scene Object](https://i.ytimg.com/vi/nxWUedX5VpQ/mqdefault.jpg)
![[CVPR 2023] Meta-Personalizing Vision-Language Models To Find Named Instances in Video](https://i.ytimg.com/vi/DnOOThEGZmU/mqdefault.jpg)
