Media Summary: Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing ... Application of Vision Language Models with ROS 2 workshop, ROS Meetup Lagos ROS Discourse Announcement ...
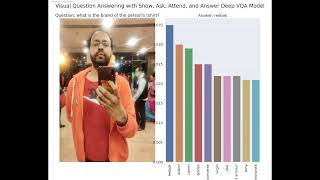
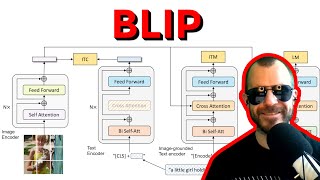
Blip Visual Question Answering - Detailed Analysis & Overview
Authors: Pan Lu (Tsinghua University); Lei Ji (Microsoft); Wei Zhang (East China Normal University); Nan Duan (Microsoft); Ming ... Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing ... Application of Vision Language Models with ROS 2 workshop, ROS Meetup Lagos ROS Discourse Announcement ... Fine Tuning BLIP CLIP for Visual Question Answering Recording Apr 7, 2026 Authors: Long Chen, Xin Yan, Jun Xiao, Hanwang Zhang, Shiliang Pu, Yueting Zhuang Description: Despite This small demo shows a Pal Robotics TIAGo++ robot executing a basic
... Vision Language Models (VLMs), which combine text and image processing for tasks like This video is a tutorial on how to get started with Authors: Xinyu Wang, Yuliang Liu, Chunhua Shen, Chun Chet Ng, Canjie Luo, Lianwen Jin, Chee Seng Chan, Anton van den ... Speaker: Asif Qamar [ SupportVectors AI Training Lab [ In this ...